Loop Engineering Explained Visually
Loop Engineering


LOOP Engineering
For two years, the standard AI workflow looked the same regardless of what you were building. Open a chat, type a request, get output, review it, type the next request. You were running the loop manually. The model executed one step and waited.
That rhythm made sense when models were unreliable. A human checkpoint at every step caught errors before they compounded. The problem is that’s no longer the constraint. The models got better. The prompting pattern didn’t change.
Agent looping replaces the manual checkpoint with an automated one.
The One-Task Problem
Every time you prompt an agent for the next step, you’re making a decision the agent should be making. Where to look. Whether the draft is good enough. What still needs work. The prompt-and-review cycle keeps you in the middle of tasks that don’t need you there.
Think of hiring a writer and calling them after every paragraph to ask what to write next. You get results, but you’re running the operation. The “automation” is expensive autocomplete with extra steps.
The fix isn’t a better model. It’s changing how you wire the agent.

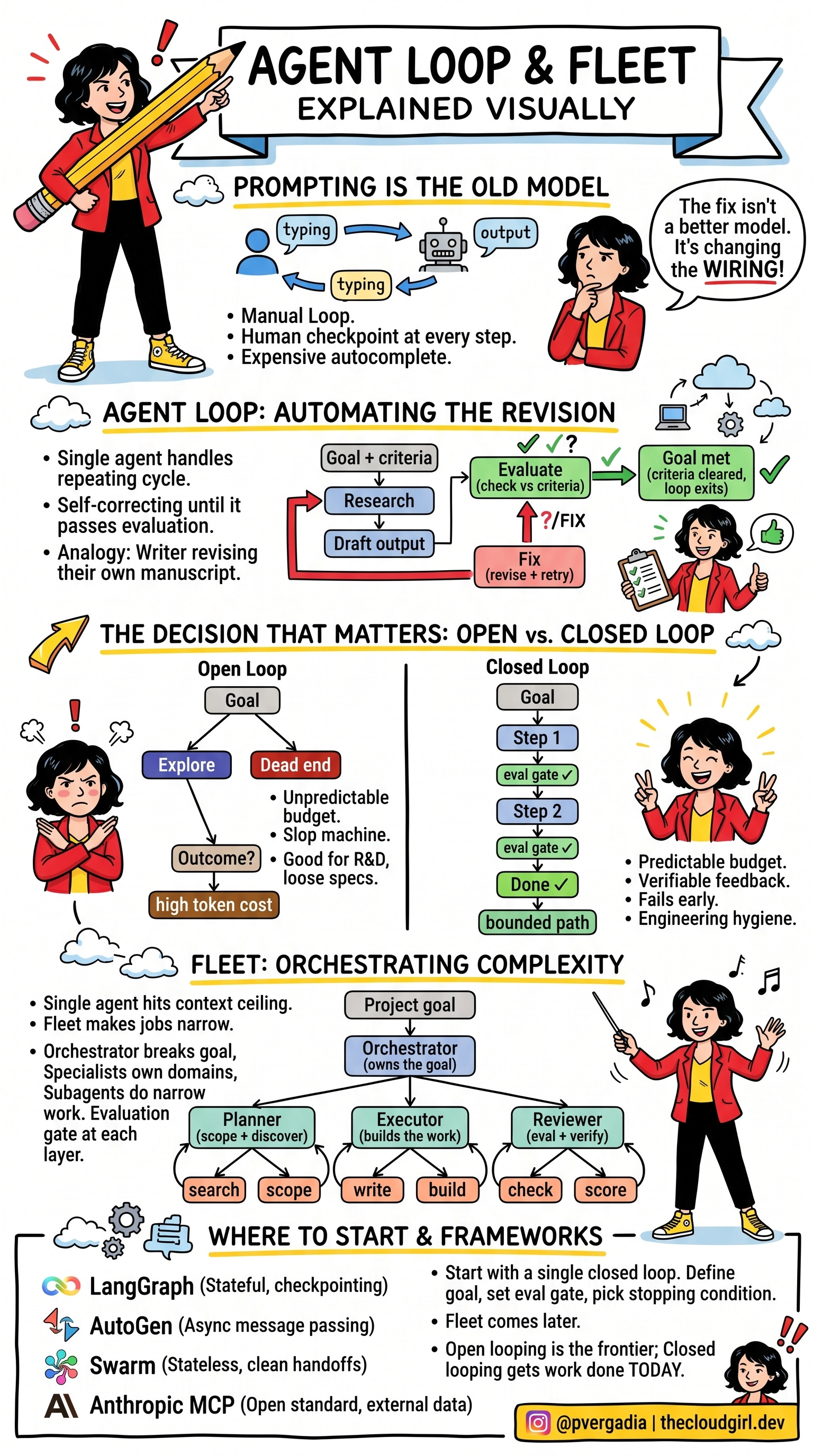
What a Loop Actually Is
A single agent loop works like this. One agent handles a repeating cycle: research the context, produce an output, check that output against a defined goal, fix what’s weak, run the cycle again. It keeps running until the output clears the criteria you set. You defined the goal and the standard. The agent runs the loop.
The analogy: a writer revising their own manuscript. They research, draft, read it back with fresh eyes, mark the weak sections, fix them, and read again. They don’t come back to the editor between every revision asking what to do next. The cycle is internal. It runs until the piece is good enough.
That’s a single agent loop. You’ve handed over the revision cycle, not just the first draft
Two things make or break the system: what counts as passing the evaluation, and when the loop stops. That’s the engineering work. Almost none of it requires a better model. Now, one agent is not enough, let me explain why and how we get to multiple loops…
When One Agent Isn’t Enough
A single agent looping handles bounded tasks well. Real projects have scope. They have research phases, execution phases, and review phases that require different cognitive modes. Forcing one agent to be a researcher, a planner, and a reviewer simultaneously is like asking your best writer to also fact-check every claim, copy-edit their own prose, and run the printing press.
The issue isn’t capability. It’s context. The more you ask one agent to hold in its head at once, the more its performance degrades. Something near the end of a long context window gets less attention than something near the front. The single-model approach hits a ceiling that has nothing to do with how powerful the model is.
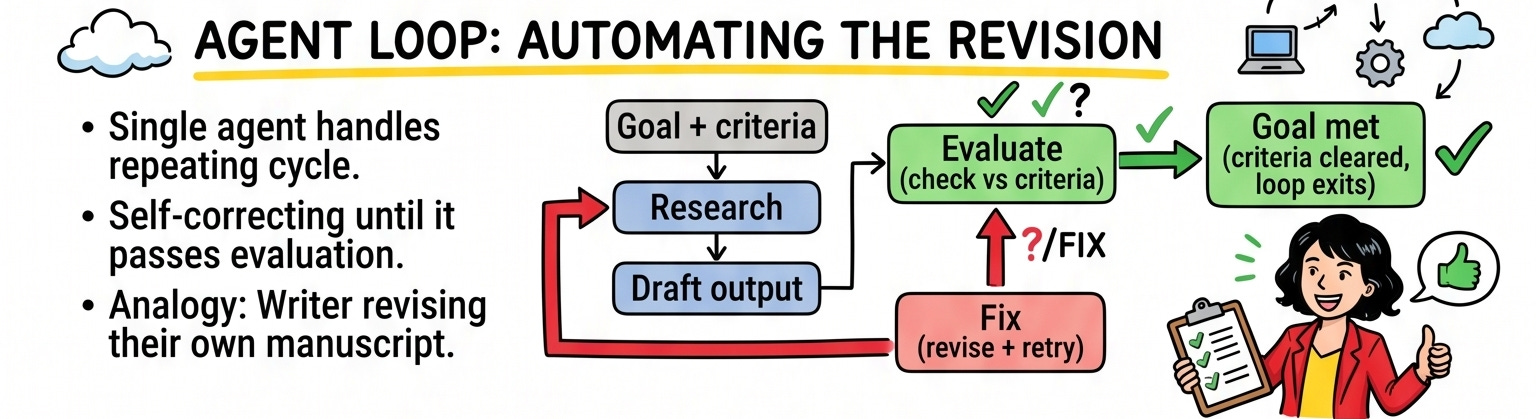
Fleet looping solves this by making each agent’s job narrow. You give a high-level goal to an orchestrator agent. The orchestrator breaks that goal into pieces and hands each piece to a specialist. Those specialists, if their pieces are complex enough, hand narrower work to their own subagents. The whole tree keeps looping through discovery, planning, execution, and verification until the goal is met.
Extend the analogy: your writer is now a managing editor. They own the brief and assign sections to specialist reporters. Each reporter runs their own research and revision cycle. Fact-checkers verify claims. Copy editors handle polish. The whole operation runs without the managing editor touching every sentence.
The orchestrator owns the goal. The specialists own their domains. The subagents do the narrow work. An evaluation gate at each layer makes sure nothing slips through.
Open vs Closed Loops
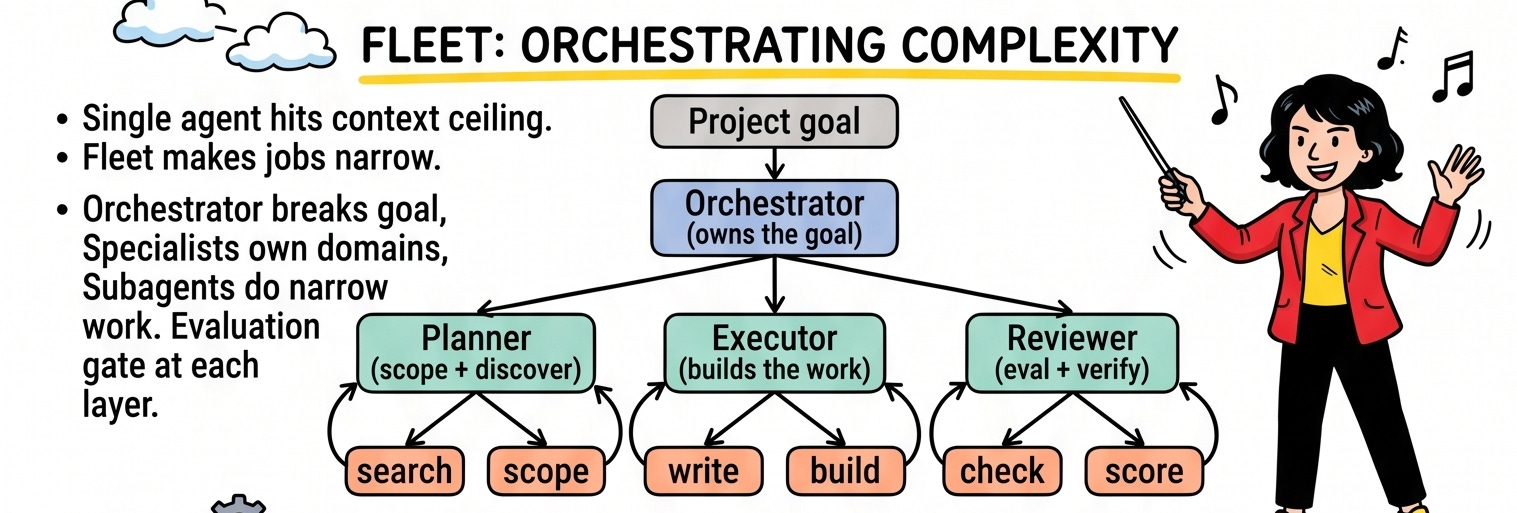
Most builders hear “agent looping” and picture a system that figures everything out on its own. Give it a vague goal, walk away, come back to finished work.
That’s open looping. It’s real, and on a research budget it’s exciting. Give an agent a wide operational space, no prescribed path, room to explore. The system can try different approaches, find solutions you didn’t spec, build something you wouldn’t have thought to ask for.
The problem is cost. An open loop exploring a problem generates chains of reasoning, many of which go nowhere. Each iteration re-processes the entire previous trajectory. The context window bloats. The API bills compound fast.
Worse: point an open loop at loose requirements and it becomes a slop machine. Without continuous grounding feedback, the agent executes its initial plan blindly and optimizes for proxy metrics rather than actual outcomes. You get output that looks like work but misses the bar. By the time you notice, you’ve paid for a lot of nothing.
Closed looping is where the commercial value lives right now. A human architect designs the end-to-end path before execution begins: clear goal, defined steps, an evaluation gate at each step, and a specific stopping condition. The agents still loop, but inside the framework you built.
Because each pass feeds the next based on verifiable feedback, the system improves with every run. Because the path is tight and failing branches stop early, it runs on a predictable budget. And because the stopping condition is explicit, you know when the work is done.
Closed loops are auditable. If something breaks, you trace exactly where it broke. You fix the evaluation, and the next run is better.
The Failure Modes
Open looping and closed looping fail differently, and the failure modes matter more than most comparisons acknowledge.
An open loop that goes wrong just keeps going. It generates plausible-looking output at scale, burns tokens with every iteration, and produces something that looks finished but misses the point. By the time you notice, you’ve paid for a lot of nothing.
A closed loop that goes wrong stops. The evaluation gate rejects the output, the loop halts, and you get a diagnostic trace telling you where things broke. You fix the eval, and the next run is better.
The preference for closed looping in production is engineering hygiene. You can always expand the operational space once the closed loop is working.
What the Frameworks Actually Solve
Building loops and fleets from scratch is possible but tedious. The orchestration frameworks solve real infrastructure problems, and the differences between them are not cosmetic.
LangGraph treats the loop as a stateful graph, checkpointing to a persistent database after every node. If execution crashes mid-loop, you resume from exactly where it failed without losing any context. For long-running agent fleets, this is more important than it sounds. A naive multi-agent loop written with standard iterative statements loses its entire context window if the underlying script crashes.
Microsoft’s Agent Framewrok uses asynchronous event-driven message passing between agents, which works well for fleets where work happens in parallel branches rather than strictly sequential steps. Their MARS deployment which automates complex repository onboarding across dozens of microservices separates the production loop from the harness loop, with a human review gate preventing the agent from unilaterally rewriting its own operational checks.
OpenAI’s Swarm goes stateless: every handoff between agents passes full context explicitly, no hidden state. The debugging experience is cleaner because there’s nothing invisible to hunt when something goes wrong. Sequential assembly-line workflows fit this model well.
Anthropic’s approach layers in the Model Context Protocol, an open standard dictating how agents discover and connect to external data sources. An orchestrator can attach tools to specialized subagents without custom integration logic for every new capability, and interrupt nodes before dangerous operations require human authorization before the fleet proceeds.
The framework choice isn’t about which is technically superior. It’s about which failure modes your team can tolerate and which debugging model fits how you work.
Where to Start
Not every workflow benefits from a loop. Build one when you’re doing the same type of work repeatedly and quality should compound with each run. When success is verifiable, not just “seems fine.” When you’re spending meaningful time driving the agent through work it could navigate on its own.
Start with a single closed loop. Define the goal concisely. Set an evaluation gate with actual criteria, not vibes. Pick a stopping condition. Wire the feedback and run it.
The fleet comes later, once the single loop works and you’ve hit the context ceiling.
Open looping is the frontier. Closed looping is where the work gets done in today’s enterprise.