
Agentic RAG Crash Course
Guide and cheatsheet to agentic RAG

In the fast-moving world of Generative AI, “RAG” (Retrieval-Augmented Generation) has become a household term. But as we move from simple chatbots to autonomous systems, the requirements have shifted. We are no longer just building search engines; we are building Agents.
An AI Agent is only as powerful as the infrastructure supporting it. To build a system that can reason, plan, and execute, you need more than just an API key—you need a robust Agentic RAG Ecosystem.
We’ve mapped out the perfect “Journey” to building this stack. Think of it as a train line: the “Agentic RAG Express.” Every station adds a critical layer of intelligence and stability to your application.
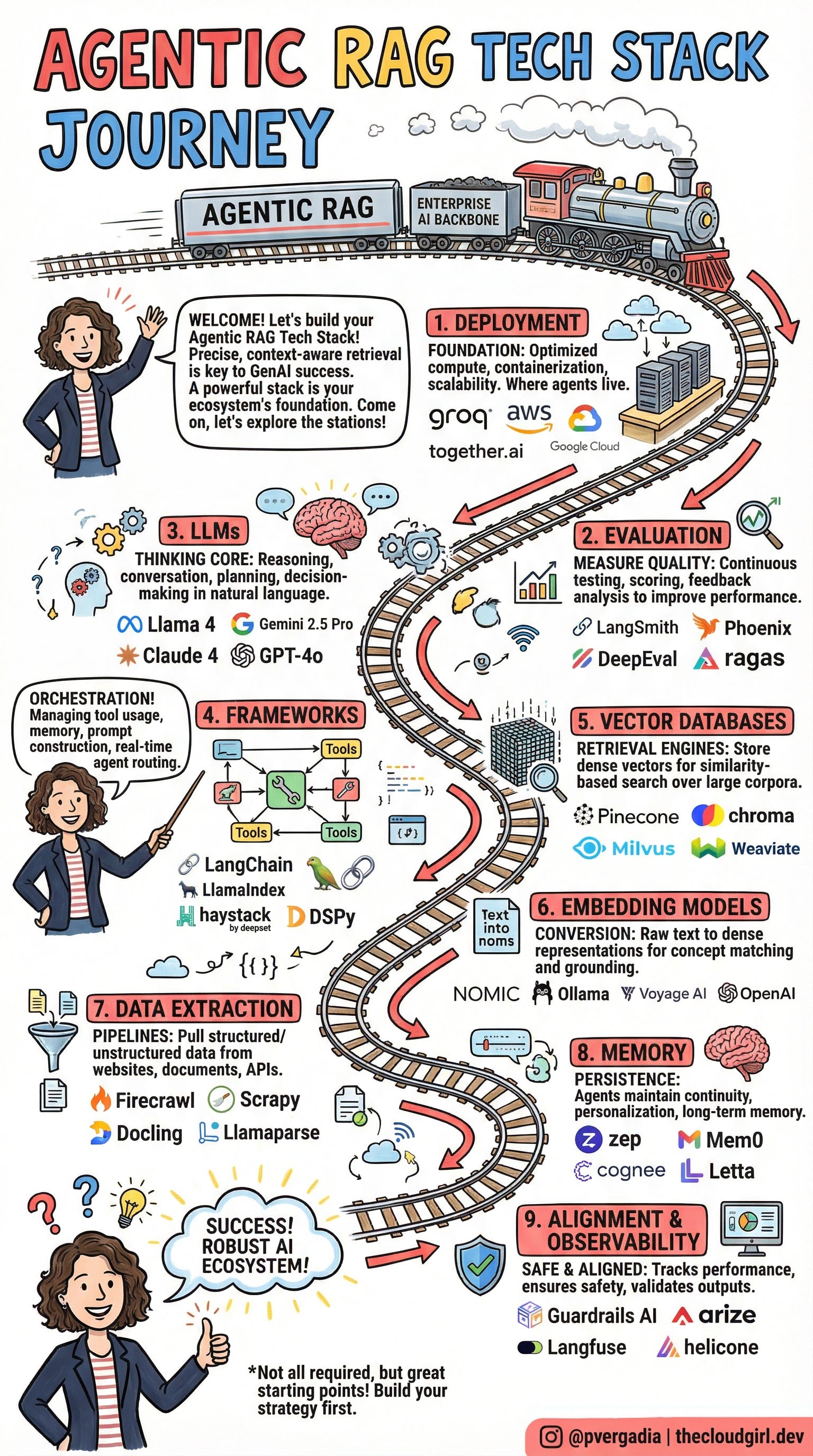
Let’s walk through the 9 Stations of the Stack.
🚉 Station 1: Deployment (The Foundation)
Status: Level 0
Before the train leaves the station, you need tracks. In the AI world, this is your compute and inference layer. This is where your agents “live.”
For Agentic workflows, latency is the enemy. Agents often require multiple inference steps (thought-action-observation loops). Therefore, your deployment strategy must prioritize optimized compute and containerization.
The Toolkit:
Inference: Groq (for ultra-low latency), Together.ai
Cloud/Containerization: AWS, Google Cloud, Azure
📊 Station 2: Evaluation
The Golden Rule: If you can’t measure it, you can’t improve it.
Many developers leave evaluation for the end. In an Agentic stack, it comes second. Because agents are non-deterministic, you need continuous testing pipelines to score the quality of retrieval and the accuracy of the generation. You need to know if your agent is hallucinating or just creative.
The Toolkit:
LangSmith & Phoenix (Tracing)
DeepEval & Ragas (Scoring metrics)
🧠 Station 3: Large Language Models (LLMs)
The Thinking Core
This is the engine of the train. In an agentic workflow, the LLM isn’t just generating text; it is performing reasoning, planning, and decision-making. It needs to understand when to call a tool, how to parse the output, and how to course-correct.
The Toolkit:
Proprietary: GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro (or the upcoming 2.5)
Open Weights: Llama 3 (and the anticipated Llama 4)
🎼 Station 4: Frameworks
Orchestration & Routing
If the LLM is the brain, the framework is the nervous system. This layer manages the “loops”—connecting the LLM to external tools, managing prompt construction, and handling the flow of data between steps. This is where you define the logic of your agent.
The Toolkit:
LangChain & LlamaIndex (The industry standards)
Haystack (For modular pipelines)
DSPy (For optimizing prompts programmatically)
🗄️ Station 5: Vector Databases
The Retrieval Engine
Agents need access to knowledge that wasn’t in their training set. Vector databases store your proprietary data as dense vectors, allowing for semantic similarity search. This allows the agent to find the “needle in the haystack” across vast corpora of corporate data.
The Toolkit:
Pinecone, Chroma, Milvus, Weaviate
🔢 Station 6: Embedding Models
The Translator
Before data enters the Vector DB, it must be converted from raw text (human language) into numbers (machine language). High-quality embedding models are crucial for “grounding” your agent—ensuring it understands the nuance of your specific domain concepts.
The Toolkit:
Nomic, Voyage AI, OpenAI Embeddings
Ollama (for running local embeddings)
⛏️ Station 7: Data Extraction
The Fuel Supply
Your vector database is only as good as the data you feed it. The Extraction station is all about ETL (Extract, Transform, Load). You need pipelines capable of pulling structured data from the unstructured “wild”—scraping complex websites, parsing PDFs, or reading raw APIs.
The Toolkit:
Firecrawl & Scrapy (Web scraping)
Docling & LlamaParse (Document parsing)
💾 Station 8: Memory
Persistence
A standard chatbot forgets you the moment you close the tab. An Agent remembers. This station adds a persistence layer, allowing agents to maintain continuity across sessions, remember user preferences, and build long-term context.
The Toolkit:
Zep, Mem0, Letta (formerly MemGPT), Cognee
🛡️ Station 9: Alignment & Observability
Safety & Cost Control
The final station ensures your train doesn’t derail. As you scale, you need to track token usage (costs), monitor latency, and ensure the agent stays within safety guardrails (preventing jailbreaks or toxic outputs).
The Toolkit:
Guardrails AI (Safety)
Arize, Langfuse, Helicone (Observability and Analytics)
The Destination: A Robust AI Ecosystem
Building an Agentic system isn’t just about picking the best LLM—it’s about how these 9 stations interact. A slow vector database bottlenecks the LLM. Poor data extraction confuses the embedding model. A lack of memory frustrates the user.
Challenge: Look at your current stack. Which station are you missing? Which station is your bottleneck?
Build your strategy first, then choose your tools.
This breakdown of the agentic RAG stack is extremly helpful! I really apprecaite the train metaphor—makes it easier to visualize how each component builds on the previous. The point about evaluation coming second (not last) is crucial and something alot of teams miss. I've seen projects struggle when they bolt on testing after everything's built. The memory station also resonates deeply—agents without persistence feel like starting from scratch every time.