
AI Engineering Developer Cheatsheet 2026
And the four mistakes I see developers making every single day

In 2024, I had a tab open for a Stanford deep learning course. Another tab: a YouTube playlist on backpropagation. A third: a Coursera specialization promising to turn me into an “AI Engineer” in six months.
I closed all of them.
Not because learning is bad. Because I was not learning the right things!
It’s important to understand that AI Engineering and Machine Learning Engineering are not the same job. Confuse them, and you’ll spend months studying the wrong things while the industry moves on without you.
)")
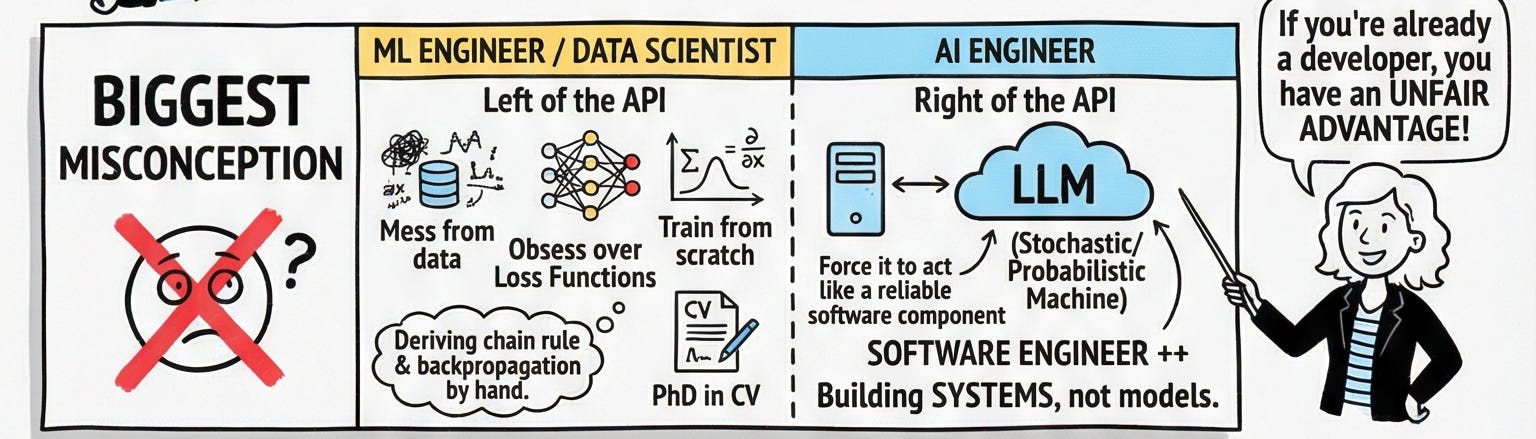
The Biggest Misconception in the Field
Imagine API as a wall. On the left side lives the ML Engineer curating datasets, obsessing over loss functions, deriving backpropagation by hand, maybe writing a PhD thesis on transformer architectures. That person is building the model.
On the right side lives the AI Engineer. That’s you. Your job isn’t to build the brain it’s to use it. You take a stochastic, non-deterministic probability machine (the LLM) and force it to behave like a reliable software component. You’re a Software Engineer Plus Plus.
If you’re already a developer, that’s actually an unfair advantage. You already understand APIs, error handling, system design, and shipping to production. You just need to learn how to tame the chaos of a model that occasionally makes things up.
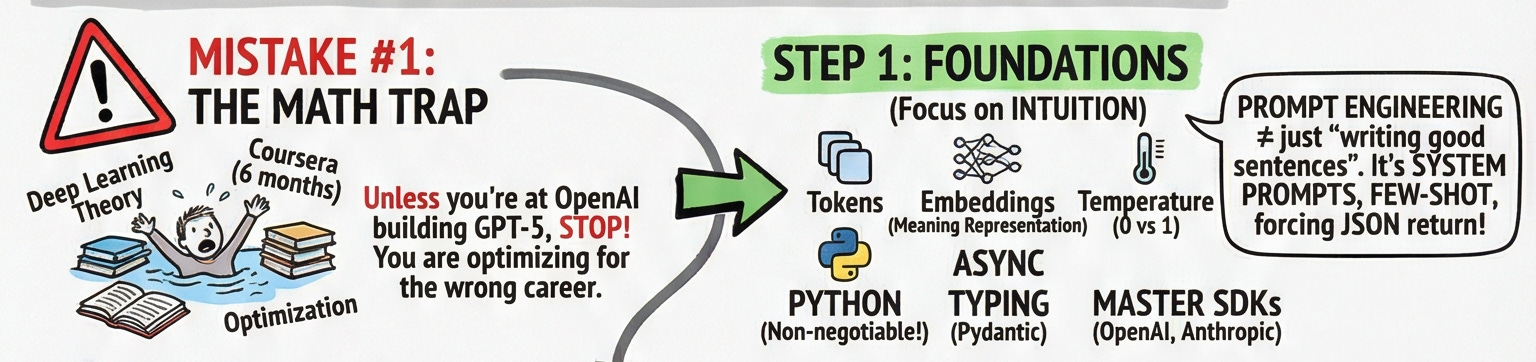
Mistake #1: The Math Trap
I know developers who’ve been “pausing their careers” for six months to grind through deep learning theory. Unless you’re planning to join OpenAI and build GPT-6 from scratch, stop. Right now.
You don’t need to calculate the chain rule. You need intuition, not derivations.
You need to understand what a token is (roughly, a chunk of text). You need to feel the difference between temperature=0 (deterministic, robotic) and temperature=1 (creative, chaotic). You need to understand that embeddings are just vectors that represent meaning in space and that similar concepts cluster together.
That’s it. The rest is building.
The actual foundation you need:
Python specifically async programming and typing with Pydantic
The SDKs: OpenAI and Anthropic (you’ll be calling these every day)
Prompt engineering and no, this isn’t just “writing good sentences.” It’s designing system prompts, using few-shot examples to condition behavior, and forcing the model to return JSON so your application doesn’t break when it gets creative
A practical example: I once had a model that returned beautifully written prose when I needed structured data for a downstream function. The app crashed. The fix wasn’t re-training anything — it was a single line in the system prompt: “You must respond only with valid JSON. No preamble. No explanation.” That’s AI Engineering.
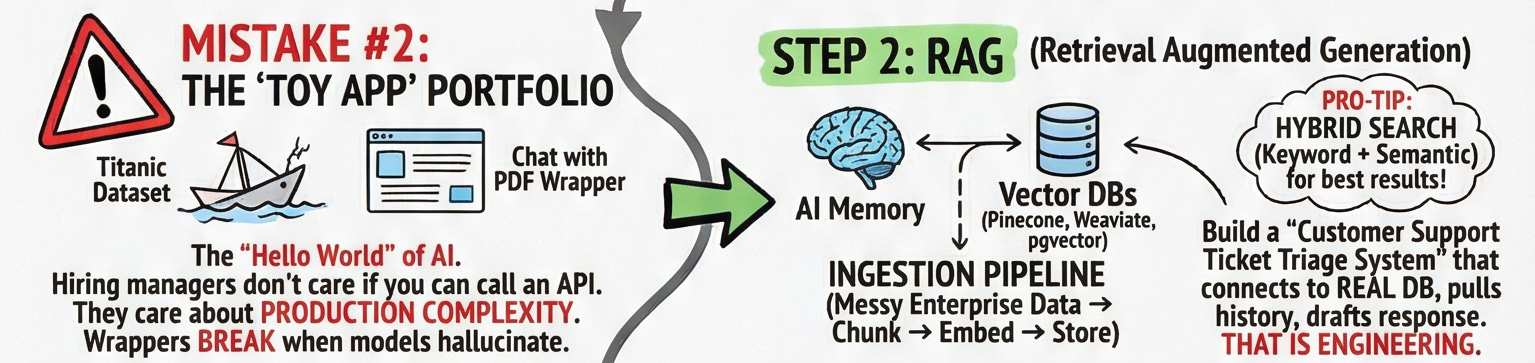
Mistake #2: The “Toy App” Portfolio
Let me be brutal: if your GitHub portfolio has a “Chat with PDF” wrapper and a Titanic dataset notebook, you are not standing out to any hiring manager in 2026. These are the “Hello World” of AI. They prove you can call an API. They don’t prove you can build a system.
Here’s the difference:
A wrapper calls openai.chat.completions.create() and returns the result. When the model hallucinates, the app breaks. When the input is weird, the app breaks. When a PDF has tables formatted strangely, the app breaks.
A system anticipates failure, handles it gracefully, retries with fallbacks, validates outputs, and logs everything so you can debug it later.
The path from wrapper to system runs through RAG Retrieval Augmented Generation. This is how you give an LLM memory and factual grounding. You feed it your own data at runtime, rather than relying on what it memorized during training.
Real RAG engineering means building an ingestion pipeline: taking messy enterprise PDFs, internal wikis, Slack exports chunking them into digestible pieces, embedding them into vector representations, and storing them in a vector database like Pinecone, Weaviate, or pgvector.
Pro tip: don’t rely solely on vector (semantic) search in production. The best systems use hybrid search combining semantic search with old-fashioned keyword matching. Semantic search finds conceptually similar content; keyword search finds exact terms. Together, they’re significantly more reliable.
Don’t build a chatbot. Build a “Customer Support Ticket Triage System” that connects to a real database, retrieves the user’s history, and drafts a contextually accurate response. That’s the portfolio item that gets you an interview.
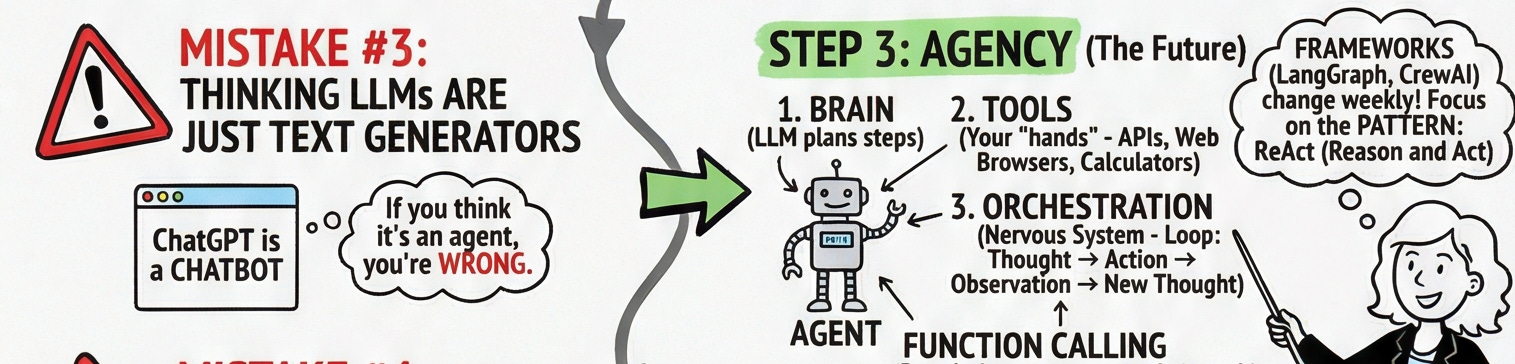
Mistake #3: Thinking LLMs Are Just Text Generators
ChatGPT is not an agent. It’s a chatbot. And if you think those are the same thing, you’re a year behind.
An agent is a system that uses an LLM to reason, plan, and execute actions autonomously without you holding its hand step by step. It has three core components:
The Brain — the LLM, which decides what to do
The Tools — APIs, calculators, web browsers, databases (the “hands” that actually do things)
The Orchestration — the loop that connects thought to action to observation and back to thought
The pattern to study is ReAct — Reason and Act. The model thinks about what to do, calls a tool, observes the result, thinks again, and repeats until the goal is achieved. You can implement this yourself. Frameworks like LangGraph and CrewAI can help, but they change weekly focus on understanding the pattern, not the library.
Here’s a concrete example: imagine an agent that monitors your GitHub issues. It reads a new issue, reasons that it needs more context, calls your internal documentation tool, reads the relevant docs, reasons that this is a bug in the authentication module, assigns it to the right engineer, and posts a preliminary diagnosis all without a human touching it. That’s an agentic system. That’s what companies are hiring for.
Function calling is the mechanism that makes this possible. You define a Python function, tell the LLM it exists and what it does, and the model decides when to invoke it. Master this, and you can wire an LLM into virtually any system.
Mistake #4: Ignoring Evals and Ops (The Fatal One)
This is where most developers completely fall apart in interviews.
Traditional software is deterministic. 2 + 2 equals 4 today, tomorrow, and in ten years. You write a unit test. It passes or fails. Simple.
AI is non-deterministic. Run the same prompt twice and you might get different answers. So how do you test a vibe? How do you know your system got better after you changed the prompt?
If you can’t answer that, you’re not ready for a production AI role.
The answer has two parts:
Observability — You need to trace every single AI call. What was the input? What was the output? How long did it take? How much did it cost? What was the exact sequence of steps that led to the wrong answer? Tools like LangFuse and Arize make this possible. Without observability, you’re flying blind, and debugging becomes a nightmare.
Evals — You need a “golden dataset” a curated set of questions with known good answers. Every time you change your prompt, your model, or your retrieval logic, you run your system against this dataset and measure whether it got better or worse. The elegant trick here is LLM-as-a-Judge: you use a capable model (like GPT-4) to grade the responses of your application model. Imperfect? Yes. But infinitely better than “eyeballing it.”
This is the part that separates engineers from tinkerers.

Your Map To AI Engineer in 2026
Here it is, clean and simple:
Foundations — Python (async, Pydantic), SDKs, prompt engineering
Architecture — RAG, vector databases, hybrid search, ingestion pipelines
Agency — tools, function calling, orchestration, the ReAct pattern
Production — observability, evals, LLM-as-a-Judge, cost and latency tracking
The best AI Engineers aren’t people who understand every mathematical nuance of transformers. They’re great software engineers who learned how to impose order on a probabilistic system. They build things that don’t break, that recover when they do break, and that get measurably better over time.
Ship small. Iterate fast. Build systems that solve real, messy, complex problems, not polished demos that collapse under real-world conditions.
That portfolio - the one with the real ingestion pipeline, the tracing dashboard, the golden eval dataset, that’s what gets you hired.
Now go build something.