
AI Evals Explained
LLM App Evaluation

Your demo worked perfectly. The AI summarized beautifully, retrieved the right documents, answered every test question with confidence. So you shipped it. Three weeks later, a user screenshots your chatbot hallucinating your own product pricing, and it’s in a Slack thread with two hundred eyes on it.
This is the oldest story in AI engineering. The gap between “worked in the demo” and “reliable in production” is exactly the gap that LLM evaluation exists to close and most teams don’t take it seriously until something embarrassing happens.
LLMs are generalized models that aren’t fine-tuned for a specific task. With a standard prompt, applications demo really well, but in production environments, they often fail in more complex scenarios. The diagram above shows the full lifecycle of a production-grade eval system pre-production, CI/CD, and live monitoring feeding back into each other. Let’s walk through why each layer exists, and what happens when you skip one.

Your LLM Is a Magic Box That Lies Occasionally
Think of an LLM like a brilliant but overconfident intern. Given a test from the curriculum, they ace it. Put them in front of a real customer with an unusual edge case, and they’ll confidently give you a wrong answer — with the same calm voice they used for the right ones.
The non-determinism is the killer detail. Traditional software testing works because add(2, 2) always returns 4. LLMs don’t have that courtesy. Run the same prompt ten times, get subtly different outputs. Some correct, some not. The standard testing playbook write a test, run it, it passes simply does not apply.
You need a way to judge the quality of your LLM outputs, judging on dimensions like relevance, hallucination percentage, and conversation correctness. When you adjust your prompts or retrieval strategy, you will know whether your application has improved and by how much using evaluation.
This is the paradigm shift. Evals are your new unit tests. They’re probabilistic, not binary. And unlike traditional tests, a “passing” eval is more like “passing at 87% precision” not a clean green checkmark.
The Two Types of Evaluator (And When Each Wins)
Before anything else, you need to choose how you’re going to measure outputs. There are two main approaches, and the teams that struggle are usually the ones that default to one and ignore the other.
LLM-assisted evaluation uses AI to evaluate AI with one LLM evaluating the outputs of another and providing explanations. This approach is often needed because user feedback or any other “source of truth” is extremely limited and often nonexistent, and it is easy to make LLM applications complex. LLM-as-judge is your workhorse for subjective quality signals: hallucination detection, relevance, tone, coherence. Anything that would require a human to read the output and make a judgment call. The evaluator LLM can be a different, possibly stronger model than your production model.
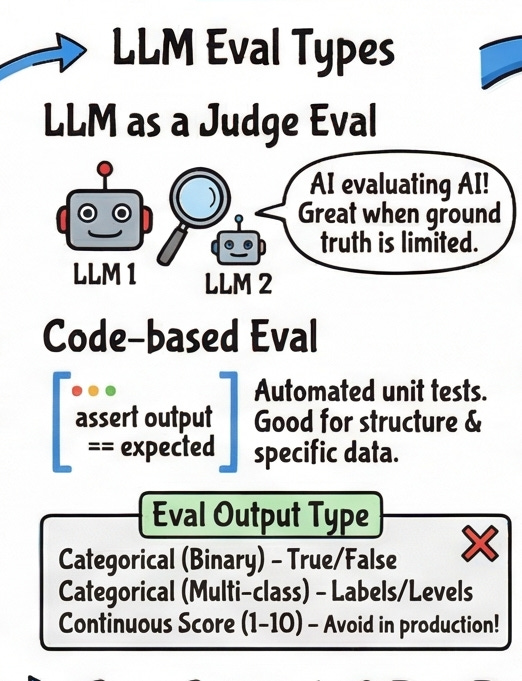
Code-based evaluation is preferred as a way to reduce costs, as it does not introduce token usage or latency. When evaluating a task such as code generation, a code-based eval is often the preferred method since it can be hard coded and follows a set of rules. Code-based evals shine for structural correctness does the output parse as valid JSON? Does the number fall within a valid range? Did the agent call the right function? These are cheap, fast, and deterministic. Run them first, run them often.
The trap is believing you can use only one. Subjective quality needs the LLM judge. Structural correctness needs the code evaluator. Build both.
Never Use a 1-to-10 Score in Production
One of the least obvious but most consequential decisions in eval design is the output format. There’s a tempting instinct to produce a score from 1 to 10 — it feels precise, quantitative, scientific. Resist it.
LLMs often struggle with the subtleties of continuous scales, leading to inconsistent results even with slight prompt modifications or across different models. Repeated tests have shown that scores can fluctuate significantly, which is problematic when evaluating at scale
Categorical evals, especially multi-class, strike a balance between simplicity and the ability to convey distinct evaluative outcomes, making them more suitable for applications where precise and consistent decision-making is important.
The three formats that actually work in production: binary (correct/incorrect, hallucinated/factual) for clear yes/no questions; multi-class (fully relevant/partially relevant/irrelevant) when nuance matters; and categorical score (1 or 0) when you want something you can average across a dataset without the chaos of a continuous range. The categorical score is the underrated one — it gives you a clean aggregate metric that’s actually interpretable.
Pre-Production: The Golden Dataset Is Everything
A common failure mode is teams who write evals but use bad data to run them against. An eval is only as trustworthy as the dataset it runs on. A limited dataset can show high scores while your application quietly fails on the inputs it never saw.
The gold standard is a curated “golden dataset” a collection of hand-crafted examples with validated ground truth. Hand-crafted examples are the simplest form of a curated golden dataset. Subject matter experts or dataset designers create examples manually to capture different aspects of the task or domain being evaluated. The strength of this approach is that it allows for the creation of nuanced and challenging examples tailored to specific use cases or edge cases
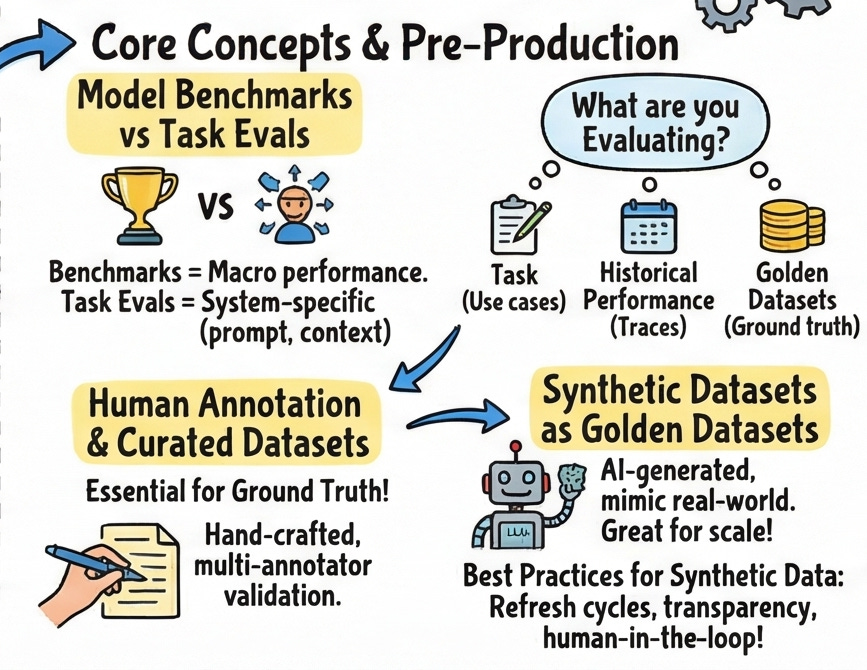
To ensure quality and reliability, it’s crucial to validate annotations across multiple annotators. A common approach is to use the consensus of at least two out of three annotators to confirm the correct label.
The practical starting point is smaller than you think. Even twenty high-quality, manually curated examples form a meaningful baseline. Once you have those, you can use synthetic data generation to scale up an LLM generating variations of your existing examples is a legitimate and effective technique, provided you’re refreshing the synthetic set regularly to avoid drift.
Now here’s where offline and online eval meet:The most important architectural insight in eval system design is that the same evaluator runs both offline and online. You build the evaluator once your hallucination detector, your relevance scorer — and it runs against your golden dataset in pre-production, then runs against live production traffic after deployment. One unified system. One consistent measurement.
CI/CD for LLMs Is Not Optional, It’s Just Harder
The place most teams underinvest is the CI/CD layer. Everyone understands running tests before shipping code. Fewer teams internalize that an LLM application can silently degrade even when no code has changed because the model itself updated, or because user input patterns drifted.
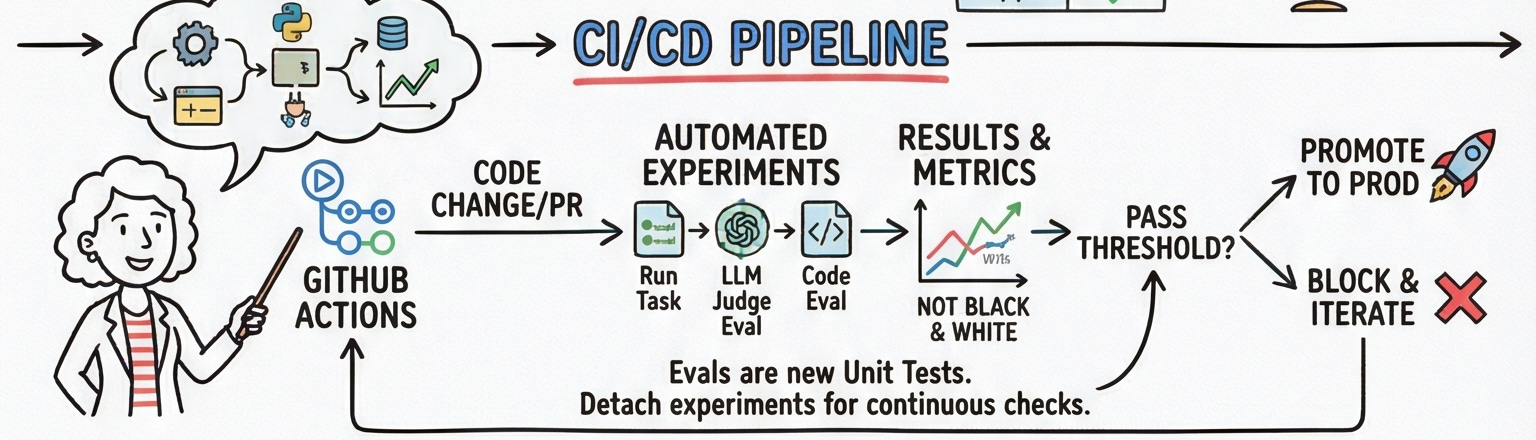
An experiment allows you to systematically test and validate changes in your LLM applications using a curated dataset. An experiment has three components: a dataset providing the inputs; a task that runs those inputs through your application and produces outputs; and an evaluator that scores those outputs. Run an experiment on every pull request. Require it to pass a threshold before merge.
Reading the results is where the nuance lives. Experiments often yield mixed outcomes some evaluations may show improvements while others may not. A change in prompt structure might lead to higher coherence scores but could slightly reduce factual accuracy. The right response is not to chase perfect scores across all metrics. It’s to understand which trade-offs matter for your specific use case, and make a deliberate choice.
One detail that’s often missed: LLM applications are also affected by model updates and input drift in production, not just code changes. As a result, experiments need to be run regularly even when there aren’t associated pull requests. Detach your evals from CI/CD and run them on a schedule too.
Guardrails Are Not a Cure, They’re a Seatbelt
Production brings a class of problems that pre-production evals can’t fully anticipate: jailbreak attempts, prompt injections, outputs that are technically coherent but violate brand policy. LLM guardrails allow you to protect your application from potentially harmful inputs, and block damaging outputs before they’re seen by a user. As LLM jailbreak attempts become more common and more sophisticated, having a robust guardrails approach is critical.
There are two ends to guard: inputs (catching malicious prompts, removing PII before it reaches the model) and outputs (catching hallucinations, toxicity, competitor mentions, NSFW content). Both matter, but output guards are often more important filtering inputs too aggressively can distort the user’s original intent.
The implementation advice that’s easy to miss: resist the urge to implement every conceivable guard at launch. Excessive guardrails risk losing the intent of the user’s initial request or the value of the app’s output. Start with the critical ones jailbreak detection, PII stripping, hallucination prevention and add more judiciously as you identify real failure patterns in production.
Dynamic guards are more robust than static ones. Few-shot prompting within the guard lets you incorporate real attack patterns as they emerge. Embedding-based guards compare user inputs against a database of known attack embeddings, so they can catch novel variations of known attack patterns rather than only exact matches.
The Decision Guide: Which Eval Approach When
Situation Approach Why Early prototyping, no production data Offline eval against 20 handcrafted examples Fast signal, cheap iteration Subjective quality (tone, relevance, hallucination) LLM-as-judge + categorical output No code evaluator can judge nuance reliably Structural output validation (JSON format, ranges) Code-based eval Cheaper, faster, fully deterministic Pre-deploy change validation CI/CD experiment with golden dataset Same as unit tests for traditional software Sensitive domain (medical, legal, financial) Human annotation + multi-annotator validation Ground truth must be trustworthy Real-time harmful output prevention Guardrails with embedding-based detection LLM judge too slow for blocking; static rules too brittle Post-deploy quality monitoring Online evals with same evaluator as offline Consistent measurement across lifecycle Sophisticated attacks (jailbreaks, prompt injection) Dynamic guards with few-shot examples Static rules can’t keep up with evolving threats Agent evaluation Skill evals + router eval + path tracking Three distinct failure modes, each needs its own metric

The overarching recommendation: start with offline evaluation and a small, high-quality golden dataset. Add code-based evals for any structurally verifiable output. Wire it to CI/CD. Deploy with guardrails for the most critical risk classes. Then let production data teach you which evals to refine next.
Your LLM is not magic. It’s a system. Measure it like one.
This is a great primer. The part that keeps coming up in practice is how differently the same model scores depending on what you're actually measuring. AISLE's cybersecurity benchmark this week showed model rankings completely reshuffled across tasks — no stable best model. Evals are only as useful as the specificity of the question you're asking them!