
Inside the NVIDIA AI Stack: How Silicon, Software, and Photonics Power the Agentic Era

I was at NVIDIA GTC 2026 and here is the breakdown of NVIDIA stack. Forget “accelerated computing.” What NVIDIA has built is something far more audacious: a vertically integrated, end-to-end platform that stretches from transistor physics to enterprise software, from copper backplanes to generative world simulations. If you’re building AI infrastructure and you haven’t internalized how these layers interlock, and you’re making architectural decisions then you are in the right place.
This article is my attempt at breaking down every layer of the NVIDIA AI stack what it is, why it exists, and why the whole thing is more than the sum of its parts.
The Inference Inflection: Why Everything Changed
Picture a data center 2023. Its job was simple: host applications, serve requests, store data. The GPU cluster in the corner is a specialist tool — powerful, expensive, occasionally used.
In 2026, that model does not work. Data centers aren’t hosting intelligence anymore. They are manufacturing it. The shift from training (a batch job you run once) to inference (a continuous, real-time operation) means the primary measure of a data center’s value is no longer “how many web requests can it handle” but “how many AI tokens can it produce per watt, per dollar, per square meter.”
This is what NVIDIA calls the inference inflection point and it changes how you design silicon, storage, networking, and software.
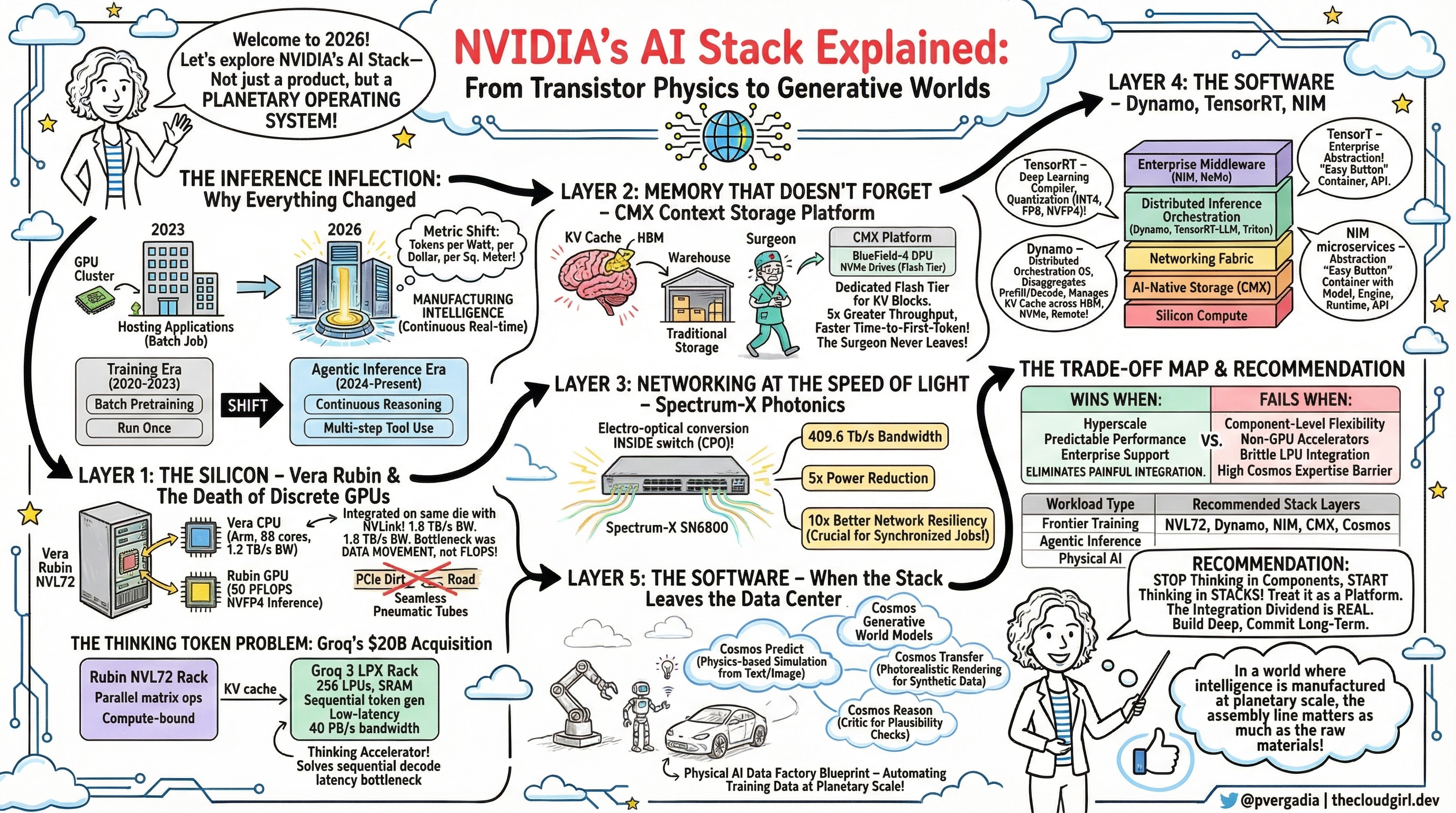
Layer 1: The Silicon: Vera Rubin and the Death of Discrete GPUs
Here’s the analogy that unlocks the Vera Rubin architecture: think of a traditional GPU server like a restaurant where the kitchen, waitstaff, storage, and dining room are all in separate buildings connected by a dirt road. Every ingredient has to be trucked across town. The Vera Rubin NVL72 is what happens when you knock down the walls and build everything in one seamless space, with pneumatic tubes running everywhere.
The platform bundles seven co-designed chips: the Vera CPU (88 custom Arm cores, 1.2 TB/s of memory bandwidth), the Rubin GPU (50 PFLOPS of NVFP4 inference per chip), and five supporting chips — all unified into a single rack-scale supercomputer containing 72 GPUs and 36 CPUs. The result is a 10x reduction in inference token cost versus the previous Blackwell generation, and 4x fewer GPUs needed to train equivalent Mixture-of-Experts models.
The architectural insight is that the bottleneck was never raw FLOPS — it was data movement. By integrating Vera CPU and Rubin GPU on the same die with 1.8 TB/s of NVLink chip-to-chip bandwidth, the platform eliminates the PCIe “dirt road” that has been strangling GPU utilization for years.
But there’s a second, subtler bottleneck that the Rubin GPU alone can’t solve.
The Thinking Token Problem
Why NVIDIA Bought Groq for $20 Billion
Agentic reasoning models don’t just answer questions. They think out loud — generating hundreds or thousands of internal “reasoning tokens” before producing a final response. This is test-time scaling, and it’s the defining computational pattern of 2026.
Here’s the problem: generating tokens sequentially is fundamentally memory-latency-bound, not compute-bound. HBM (High Bandwidth Memory) — the memory architecture at the heart of every GPU — is brilliantly optimized for massively parallel operations. It is not optimized for the low-latency, sequential decode phase that makes an agent feel instantaneous.
This is why NVIDIA executed a $20 billion acquisition of Groq and its Language Processing Unit architecture. The LPU does something heretical: it replaces HBM entirely with on-chip SRAM. SRAM is 100x more expensive per bit than HBM — but it delivers 40 petabytes per second of bandwidth in a single rack, with vastly lower latency per sequential access.
The resulting Groq 3 LPX rack is not a general-purpose compute system. It’s a dedicated thinking accelerator. In the Vera Rubin factory architecture, Rubin GPU racks handle the heavy lifting (pre-filling massive context windows, batch matrix operations), while adjacent LPX racks handle the latency-sensitive decode phase. It’s a division of labor that maps perfectly to the two fundamentally different computational shapes of modern inference.
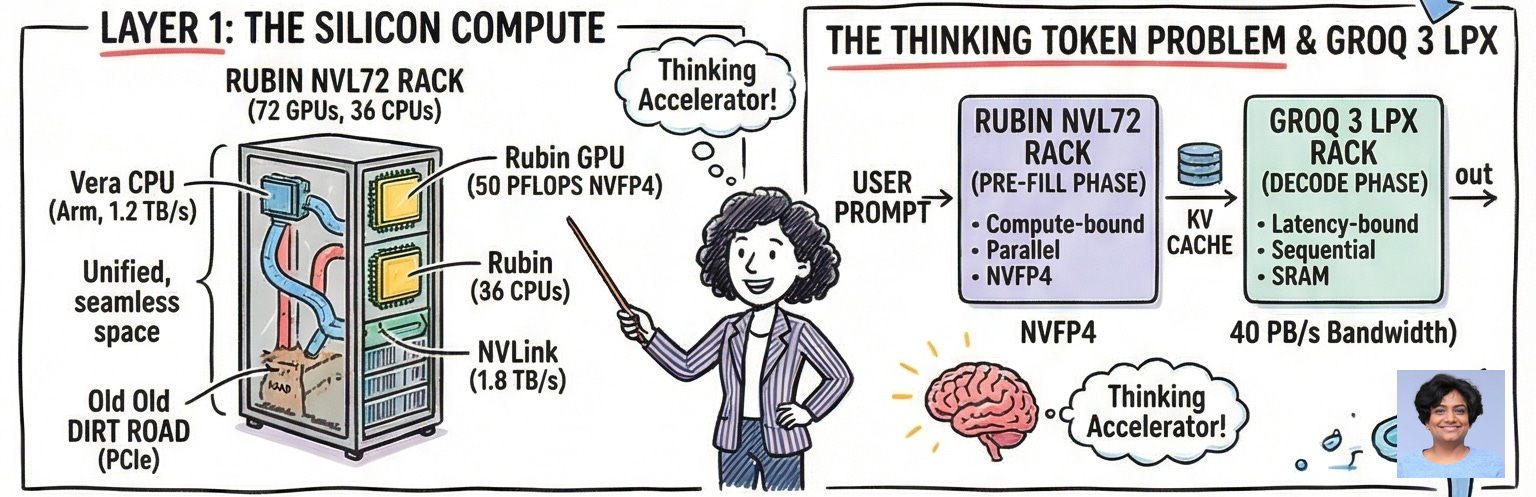
Layer 2: Memory: The CMX Context Storage Platform
The analogy here is surgical. Imagine a surgeon who, in the middle of an operation, has to periodically walk out of the building to retrieve the patient’s file from a warehouse across the street. That’s what happens to a GPU inference cluster when KV cache — the agent’s working memory — overflows its on-chip HBM and has to spill to traditional CPU-managed storage.
As context windows expand into the millions of tokens, and agents maintain coherent sessions across hours of multi-step work, the KV cache grows enormous. GPU HBM holds a few terabytes at best. When the cache misses and has to traverse standard storage paths, GPU utilization plummets and the agent effectively loses its train of thought.
NVIDIA’s solution is the Inference Context Memory Storage Platform (CMX), built around the BlueField-4 DPU. CMX inserts a dedicated flash storage tier directly between the GPU HBM and traditional data center storage. The BlueField-4 manages local NVMe drives, runs localized storage services, and exposes simple key-value APIs via the DOCA Memos SDK — effectively turning Ethernet-attached flash into a pod-level cache for KV blocks.
The results are not marginal: 5x greater token throughput, dramatically faster time-to-first-token on multi-turn sessions, and 4-5x improvement in energy efficiency. The surgeon never leaves the operating theater.
Layer 3: Networking: Spectrum-X Photonics
Scaling AI inference to hundreds of thousands of GPUs requires moving incomprehensible volumes of data between nodes continuously. Traditional electrical signaling across copper and pluggable optical transceivers hits a wall: too much power, too much heat, too much signal degradation.
The Spectrum-X Ethernet Photonics system solves this by moving the electro-optical conversion inside the switch package itself — co-packaged optics (CPO) on the same ASIC. The resulting SN6800 switches deliver 409.6 Tb/s of switching bandwidth with a 5x power reduction per port. More importantly, the architecture provides 10x better network resiliency.
That last number matters more than it looks. In a synchronized distributed training or inference job, a single link failure doesn’t cause one node to slow down — it causes thousands of GPUs to stall in unison, waiting for the failed node to catch up. Network reliability at this scale is existential for economics
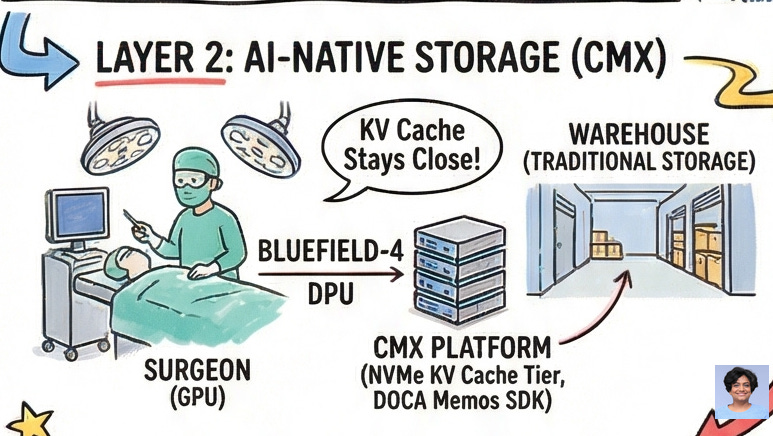
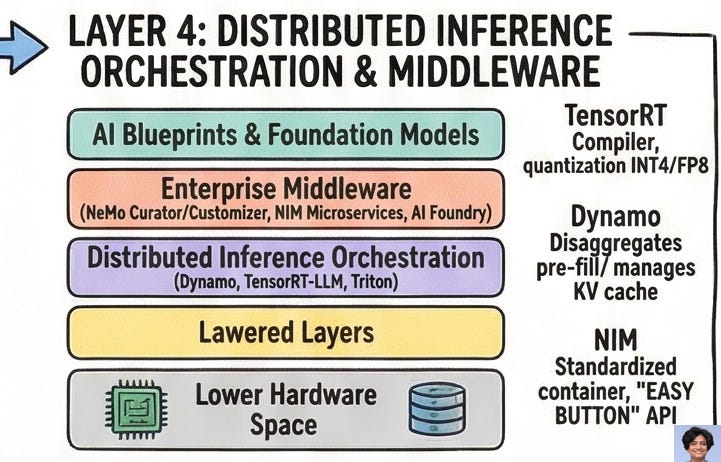
Layer 4: The Software: Dynamo, TensorRT, NIM
Raw hardware is just potential energy. The software stack converts it into work.
TensorRT is NVIDIA’s deep learning compiler. It takes a trained neural network, analyzes its graph, fuses layers, auto-tunes kernels, and emits a deployment artifact optimized for specific GPU architectures. For the agentic era, the headline feature is quantization: TensorRT compresses trillion-parameter models into INT4, FP8, and the new NVFP4 formats, dramatically reducing memory footprint without catastrophic accuracy loss. This is what makes deploying a 1-trillion-parameter model on a constrained edge device even thinkable.
Dynamo is the distributed inference orchestration layer that nobody talks about enough. It solves the problem of serving trillion-parameter models that don’t fit on any single rack. Dynamo disaggregates the pre-fill and decode phases, routing them to different GPU pools, and orchestrates KV cache movement across the entire memory hierarchy — from on-chip HBM to BlueField-4 NVMe to remote storage. When paired with NVLink, Dynamo improves MoE model throughput by 50x over unoptimized baselines. It’s deployed natively in Kubernetes environments on AWS, Azure, GCP, and Oracle Cloud. It is, functionally, the operating system for distributed inference.
NIM microservices are the enterprise abstraction on top of all of this. A NIM is a container: model weights, inference engine, runtime dependencies, and a standardized REST API, all packaged together. A developer consuming a NIM doesn’t need to know what CUDA version is running, what quantization scheme was applied, or what TensorRT fusion was performed. They call an API. The NIM handles everything else. This is the “easy button” — and it is explicitly designed to run identically in a hyperscale cloud or a private on-premises cluster.
Layer 5: Physical AI: When the Stack Leaves the Data Center
The most ambitious part of NVIDIA’s 2026 roadmap is its bet that the next economic frontier isn’t language — it’s physics.
Autonomous vehicles, industrial robots, and warehouse automation systems need to understand the 3D world: gravity, occlusion, material properties, collision dynamics. Teaching this traditionally requires enormous quantities of real-world sensor data, which is dangerous and slow to collect.
Cosmos solves this with generative world foundation models. Cosmos Predict generates 30-second physics-based video simulations from text or image prompts — allowing an AV model to simulate thousands of edge-case scenarios from a single real-world clip. Cosmos Transfer applies photorealistic rendering to synthetic 3D simulations, creating training data that is structurally accurate and visually indistinguishable from reality. Cosmos Reason acts as a critic, providing common-sense feedback on generated synthetic data to ensure it passes physical plausibility checks.
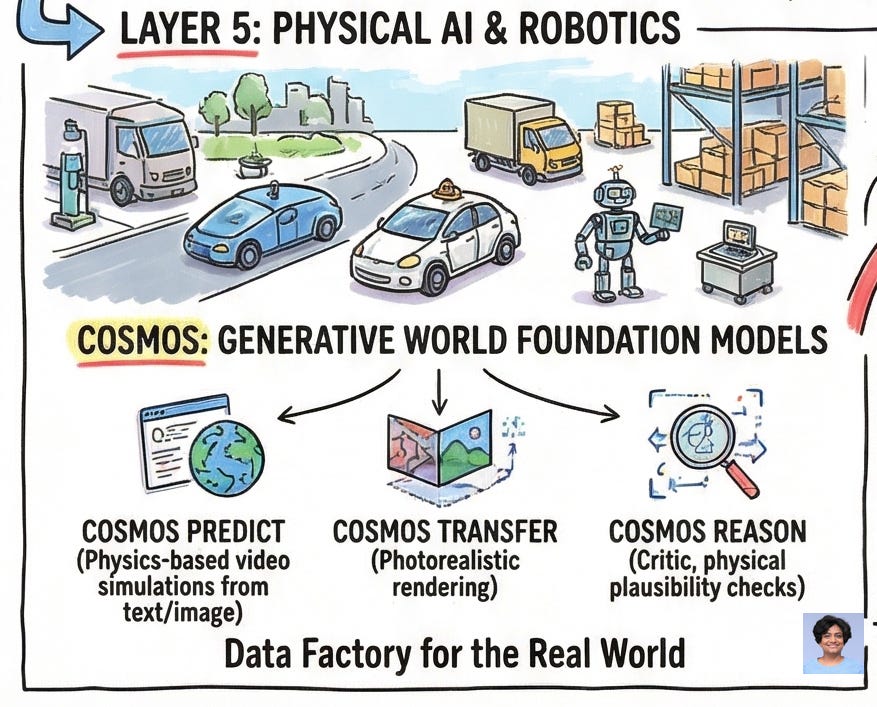
Paired with the Physical AI Data Factory Blueprint, these models transform cloud compute into an automated training data factory — generating, augmenting, and evaluating physical AI training datasets at a scale that would be impossible to collect in the real world.
The Trade-off Map: Where This Stack Wins and Where It Doesn’t
No architecture is universally correct. Here is NVIDIA’s stack evaluated honestly:
Tight vertical integration wins when your workload runs at hyperscale, you want predictable performance across the entire pipeline, and you need enterprise support for every layer from silicon to API. If you’re building a frontier model or a production agentic system, the NVIDIA stack eliminates an enormous amount of painful integration work.
Tight vertical integration fails when you need component-level flexibility. If you want to swap in a different networking vendor, use alternative storage architectures, or run on non-GPU accelerators, the stack resists you. The coupling that makes it fast also makes it rigid.
The LPU integration is smart but immature. The Groq 3 LPX deliberately skips NVLink and avoids CUDA dependencies — NVIDIA’s own decision, intended to accelerate time-to-market. The tradeoff is that the LPX racks are not yet first-class citizens in the software orchestration layer. Dynamo routes KV cache across HBM and NVMe fluidly; LPX integration is more brittle today.
Cosmos is a genuine breakthrough — for well-capitalized teams. Generating useful physical AI training data with Cosmos requires deep expertise in simulation, validation pipelines, and photorealistic rendering. The Data Factory Blueprint helps, but this is still not a turnkey capability for a 10-person robotics startup.
The ecosystem multiplier is real, but so is the dependency. NVIDIA’s modeled ratio of $8-10 in downstream software value per $1 of hardware is plausible and supported by historical analogies (the PC ecosystem, the cloud ecosystem). It also means that if you build deep on this stack, you are making a long-term commitment to NVIDIA’s architectural decisions.
Stop Thinking in Components, Start Thinking in Stacks
The central insight of the architecture is this: the bottleneck is never where you think it is. You can buy the fastest GPU in the world and starve it of KV cache data. You can optimize your model to NVFP4 precision and then watch it stall because your network drops a link. You can deploy NIM microservices and find that your storage latency is destroying time-to-first-token. Every layer creates the ceiling for the next.
NVIDIA’s answer is to own every ceiling simultaneously. When the silicon, memory, networking, storage, orchestration, and application layers are all co-designed, optimizing one tier automatically benefits the others.
What is clear is this: the organizations that understand the AI stack as a cohesive system rather than a menu of discrete hardware and software purchases will deploy agents faster, cheaper, and at greater scale than those who don’t. In a world where intelligence is manufactured at planetary scale, the assembly line matters as much as the raw materials.