Prompt Caching Visually Explained
Prompt caching: The most underused cost optimization in LLM engineering

Your AI application is hemorrhaging money on tokens it has already paid for. Every request, every turn, every user: your system prompt goes in fresh, your tool definitions go in fresh, your 50-page reference document goes in fresh. The model re-reads all of it before generating a single character of output. You are, quite literally, paying to re-read the same instruction manual thousands of times a day.
Prompt caching fixes this. Not by being clever about what you ask, but by storing the model’s internal understanding of your static content so the next request can skip straight to the part that’s actually new. Here is what Prompt Caching is visually before we dive deeper into it.
Your model is doing homework it already finished
Picture a brilliant contractor you hire to read a 200-page legal brief and then answer questions about it. First day, they read the whole thing. Fair enough. But imagine if, every single time you called them with a new question, they started from page one again. Cover to cover. Before answering anything.
That’s what your LLM is doing right now.
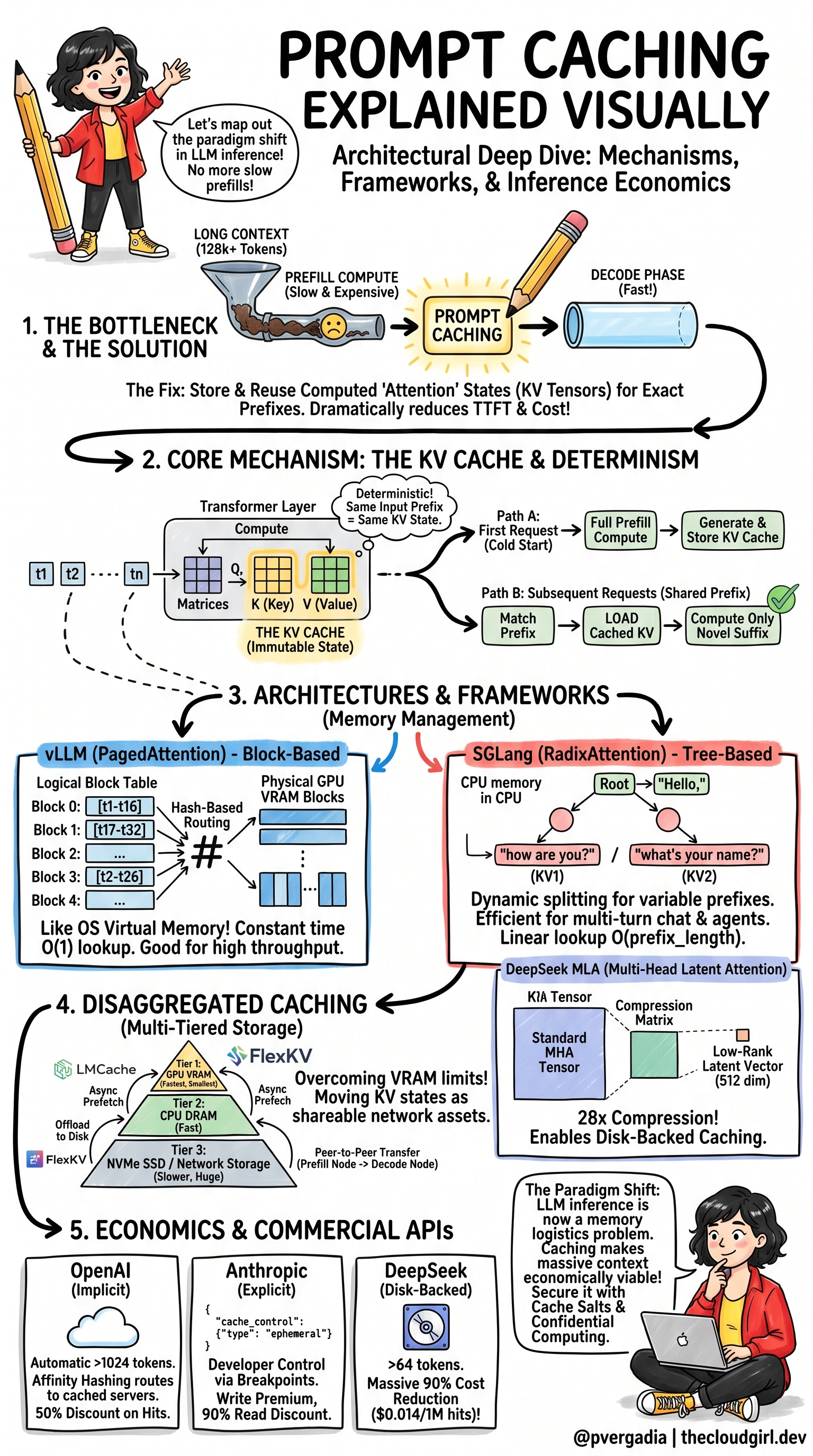
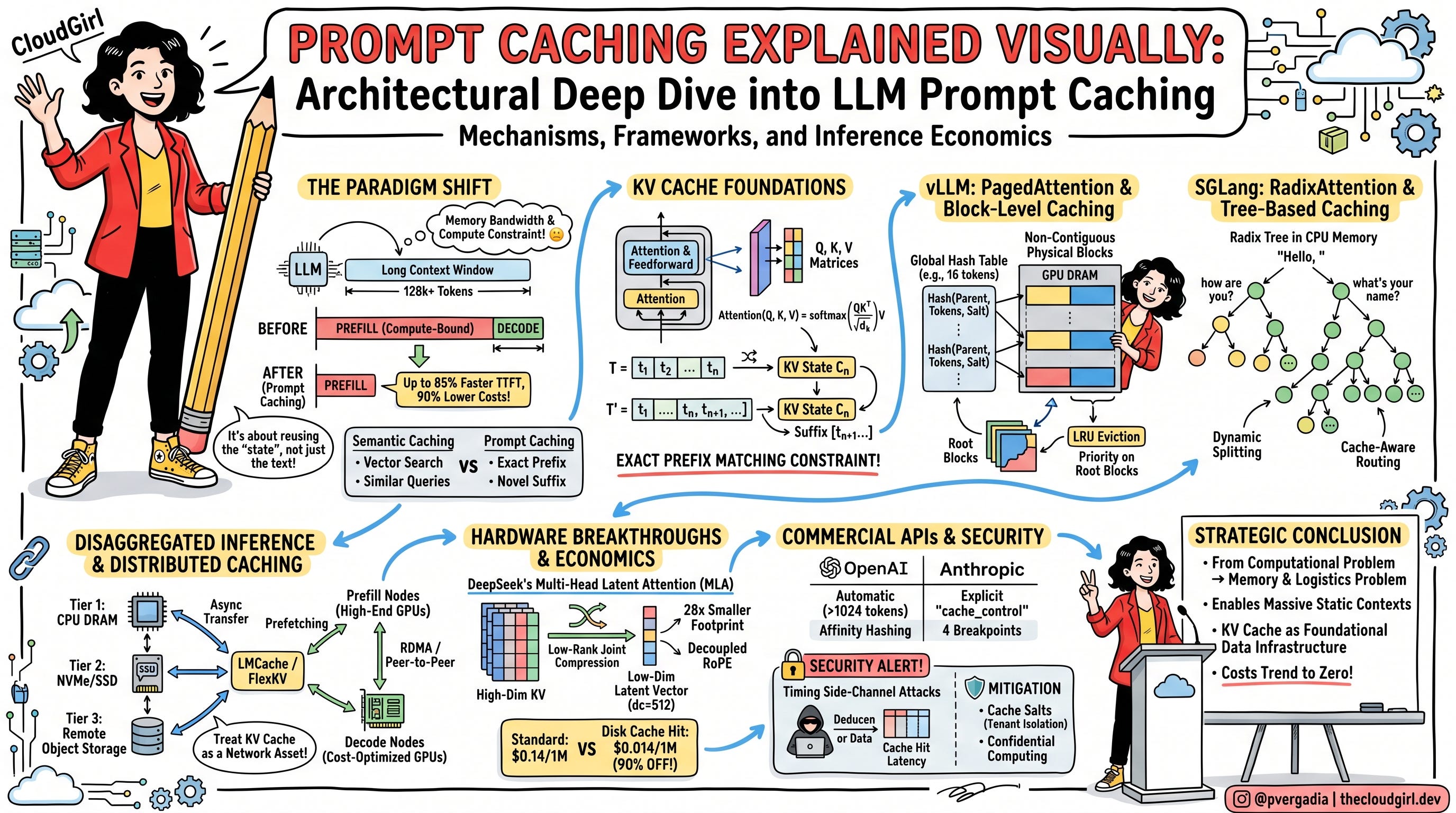
When a model processes a prompt, it converts every token into internal mathematical representations called Key and Value tensors (the KV cache). These tensors capture the model’s understanding of the context: what every word means in relation to every other word. For a long system prompt, generating these tensors is expensive. It scales roughly quadratically with sequence length. And here’s the critical insight: for an identical prefix, these tensors are always exactly the same. The computation is entirely deterministic. There is no reason to redo it.
Prompt caching stores those tensors after the first computation and hands them to the next request that starts with the same prefix. The model skips the expensive re-reading and jumps straight to processing the new content at the end. Time to first token drops by up to 85%. Input costs drop by up to 90%.
What actually lives in the KV cache
To understand caching, you need a quick mental model of what happens inside a transformer when it processes your prompt.
Each token gets converted to numbers, then passed through dozens of layers. In each layer, the model asks: “how much should this token attend to every other token?” To answer that, it computes three projections for every token: a Query (what am I looking for?), a Key (what do I contain?), and a Value (what should I contribute?). Attention scores come from matching queries against keys, then using those scores to weight the values.
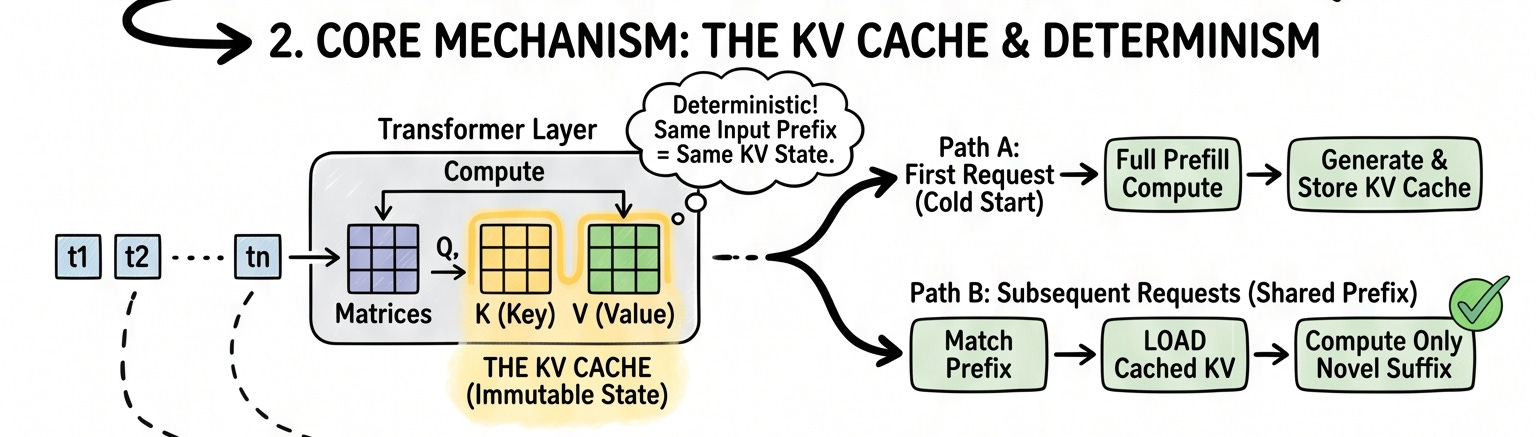
The Keys and Values for every token, at every layer, are what get cached. They represent the model’s fully-processed understanding of your text. Once computed, they are mathematically fixed. Same tokens, same order, same result. Every time.
When a new request arrives sharing your prefix, the engine loads these stored tensors instead of recomputing them, and only runs the full computation for the new tokens at the end.
The rule that changes how you write prompts
Prompt caching has one non-negotiable constraint: the match must be exact from the very first token.
Change a comma in your system prompt? Different cache.
Reorder two fields in your JSON tool definition? Different cache.
Inject the current date at the top of your context? Different cache for every single minute of the day.
This is just physics. The attention mechanism computes each token’s meaning relative to everything before it. Alter token 12, and tokens 13 through 50,000 all compute differently. The entire downstream KV cache diverges from that point forward.
The practical implication is stark: structure your prompts so everything static goes first, everything dynamic goes last.
Static content includes system instructions, tool schemas, reference documents, few-shot examples, and anything else that doesn’t change between requests. Dynamic content is the user’s message, the current date, any real-time context. Static at the top, dynamic at the bottom. This single habit is worth more than any other optimization you’ll make to your LLM application.
How the engines actually store this
Under the hood, inference engines use two main approaches to store and retrieve cached KV tensors, and they make different bets about the shape of your workload.
vLLM divides the KV cache into fixed 16-token blocks and assigns each block a deterministic hash based on its contents and its position in the sequence. When a new request arrives, the engine checks whether each of its blocks already exists in the hash table. If yes, it maps the request directly to the existing physical memory without copying anything. This approach has constant-time lookups and works well for high-throughput batch scenarios.
SGLang takes a different approach: it stores the entire cached state as a radix tree, a compressed structure where every path from root to leaf represents a cached prefix. This means two prompts that share 800 tokens but diverge on token 801 can share exactly those 800 tokens worth of KV state, regardless of where the block boundaries fall. SGLang can even split an existing cached node dynamically when a new prompt diverges mid-block. The result is significantly better cache utilisation for conversational workloads and RAG pipelines, at the cost of slightly more complex bookkeeping.
Both systems use LRU eviction when GPU memory fills up: the least recently used cached states get dropped first. vLLM preserves root blocks (shared by many prompts) as long as possible. SGLang uses pluggable policies including LRU, LFU, and FIFO depending on the access patterns of the workload.
What the major providers actually give you
The three providers with serious caching implementations all make different tradeoffs, and understanding them is the difference between saving 90% on your bill and wondering why your cache hit rate is mysteriously zero.
OpenAI does it automatically. Any prompt over 1,024 tokens gets cached, with hits detected in 128-token increments. You pay 50% of the normal input price on cache hits. You don’t opt in, you don’t mark anything, you don’t think about it. The downside is that you also have no control. Cache hits depend on server affinity: the same physical server that processed your prompt recently needs to handle the new request. Under high concurrency, the load balancer routes overflow requests to other servers that don’t have the cache, and you get misses you can’t predict or fix. OpenAI provides a prompt_cache_key parameter to influence routing, but it’s a hint, not a guarantee.
Anthropic requires you to be explicit. You mark specific locations in your prompt with a cache_control parameter to indicate where the cache boundary sits. You can place up to four of these markers per request. The benefit is precision: you control exactly what gets cached, and you understand why. The tradeoff is that writes cost 1.25x the normal input price for a 5-minute cache, or 2x for a one-hour retention window. Reads cost 0.1x (a 90% discount). The break-even for a 5-minute cache is two reads. If a cached block gets hit twice, you’ve already recovered the write premium and every subsequent hit is pure savings.
DeepSeek caches automatically to disk rather than GPU memory, enabled by their Multi-Head Latent Attention architecture which compresses the KV cache by 28x. This compression is what makes disk-backed caching practical: where a standard model might generate 213 GB of KV state for a 128k context, DeepSeek’s architecture produces 7.6 GB. Cached reads cost $0.014 per million tokens against $0.14 for standard computation, a 90% reduction, and the cache persists for hours. The architectural innovation here is significant: DeepSeek essentially made the caching problem cheaper by redesigning the model itself.
The security problem nobody tells you about
Storing computational state on shared servers creates a timing side-channel that is genuinely dangerous in multi-tenant environments.
Here’s the attack. A cache hit is fast — sometimes under a second for a 10,000-token prompt. A cache miss is slow — potentially 9 seconds for the same prompt. If a shared inference cluster lets User A’s cached KV state be served to User B’s request, an attacker can probe whether a specific prefix is in the cache by measuring response latency. Fast response confirms someone recently sent that prefix. Iterate with a binary search and you can reconstruct confidential system prompts, user conversations, or proprietary document content without ever being authorised to access them.
The standard mitigation is a cache salt: a cryptographic key tied to each tenant that gets mixed into the hash function used to identify cached blocks. With salting, identical prompts from two different organisations produce completely different block hashes and therefore never share physical memory. Same caching benefit within a tenant, zero cross-tenant visibility.
vLLM supports this directly. The salt goes into the block hash as a third input alongside the parent block’s hash and the token IDs. An attacker measuring timing gets nothing, because their salt makes their probe map to a different physical location than the victim’s cached data.
If you’re building on a self-hosted inference stack and serving multiple customers from the same cluster, implementing cache salts is not optional security hygiene. It’s the difference between a cache and a side-channel oracle.
When prompt caching genuinely wins and when it doesn’t
Prompt caching is extraordinary when your system prompt is large (500+ tokens), your reference documents are static, your users generate many requests against the same context, or you’re running multi-turn conversations where history accumulates. Code assistants, customer support bots with large policy documents, RAG systems with stable retrieved context, and document analysis tools all benefit enormously.
Caching struggles when your static prefix is short (under 1,024 tokens for OpenAI, or simply not worth the write premium for Anthropic), when users have highly personalised prefixes that differ from each other, or when you inject dynamic content into the middle of your prompt rather than the end.
The worst case is paying Anthropic’s write premium and then never getting a second hit. A 2x write premium on a block that’s only read once means you paid double for nothing. If your traffic is sparse, your context is short, or your prompts vary substantially between users, a simpler approach without explicit cache control may cost less.
The recommendation
Structure your prompts with static content first and dynamic content last. This is worth doing regardless of provider, regardless of cache hit rates, and regardless of whether you’ve done any profiling. It costs nothing and you can’t lose.
Beyond that: if you’re running Claude with prompts over 1,024 tokens that stay stable across requests, add cache_control markers now. Run a week of traffic with and without caching and look at your actual hit rates. For most production assistant workloads, the break-even is so low (two reads) that the math is settled before you finish the analysis.
If you’re on OpenAI, you’re already getting caching for free on long prompts, but audit your prompts for dynamic injections at the top. A timestamp in your system prompt header is costing you every hit.
And if you’re self-hosting, invest in the cache salt infrastructure before you have a timing attack to explain to a customer.
The compute cost of LLM inference is not going down from hardware improvements alone. Prompt caching is the lever you can pull today.